This post introduces some basic asynchronous message passing patterns that I’ve found useful while implementing real-time audio software. The patterns apply to in-process shared memory message passing. For the most part this post is intentionally abstract. I won’t talk too much about concrete implementations. I do assume that the implementation language is something like C/C++ and that the message queues are implemented using lock-free ring buffers or similar. For a motivation for this style of programming see my earlier post.
This post isn’t the whole story. Please keep in mind that there are various ways to combine the patterns, and you can layer additional schemes on top of them.
Meta
I wanted to enumerate these basic patterns to give me some clarity about this approach to writing concurrent software. While writing this post I started to look for a mathematical formalism that could capture the semantics of this kind of asynchronous message exchange. I looked at process algebras such as the actor model and pi-calculus but they didn’t seem to model asynchronous message exchange, distributed state and atomic state transitions the way I have done it here. To me the approach presented here seems similar to what you might use to model bureaucratic processes involving asynchronous exchange of paper forms and letters. If you know of an existing formalism that might be used to model these patterns please let me know in the comments, I’d love to hear about it. Thanks!
Introduction
Communication between execution contexts
This post focuses on patterns of asynchronous message exchange between a pair of execution contexts.
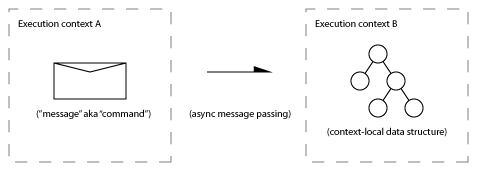
I use the term “execution context” instead of “thread” because I’m thinking not only of threads but also of interrupt handlers, signal handlers, timer callbacks, and audio callbacks. An execution context might also be the methods of an object that only operates in one thread at a time, but may migrate between threads during the course of program execution.
Some execution contexts impose certain requirements, such as not blocking (see my earlier post for a discussion of what not to do in audio callbacks).
I assume that the contexts share the same address space, so it is possible to pass pointers to objects between contexts.
I assume that processing a message is atomic and non-re-entrant with respect to the receiving execution context.
Passing messages via queues
When I talk about asynchronous message passing I have in mind an implementation where messages are communicated between threads using queues. The sender and receiver operate asynchronously. The sender doesn’t usually block or wait when sending a message. The receiver chooses when to collect and interpret messages. The queues are light-weight data structures often implemented using lock-free ring buffers. Writing to and reading from a queue are non-blocking operations. The diagram below illustrates the scheme:
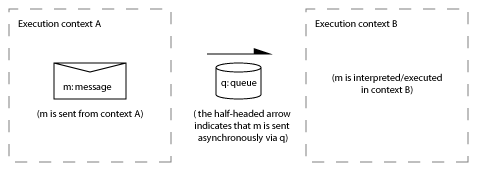
In all of the diagrams in this post the left hand side is one context, the right hand side is another context (sometimes called the sender and receiver, or source and target). The half-headed arrow indicates that a message is passed asynchronously in the direction of the arrow by writing a message into the queue from one context and reading the message from the queue in the other context at some later time.
From the perspective of each of the two contexts, code for the above diagram might look something like this:
// execution context A:
{
// post a message:
q.write( m );
}
// ... some time later
// execution context B:
{
// receive and interpret pending messages
while( !q.empty() ){ // in this case we don’t block if the queue is empty
Message m = q.read();
interpret_message( m );
}
... continue other processing
}
I’ve shown messages being passed by value (i.e. copied into a ring buffer). For small messages and single-reader single-writer queues this usually works out well. I mention some other variations later.
To send a message in the opposite direction (from context B to context A) a second queue is needed:
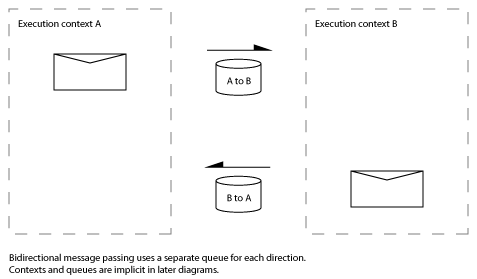
For the rest of this post I’m not going to explicitly notate the contexts and queues: when you see a half-headed arrow it means that the message is being passed asynchronously from one context to another via a non-blocking queue.
Program organisation: a network of message queues and execution contexts
There are different ways to connect between the various execution contexts and objects of a program with message queues. Some options that can be used in combination are:
- Fixed topology of contexts and queues. A static network of queues are used to pass messages between contexts. In the extreme, contexts may “own” a queue for receiving messages and run an event loop — like the post message/event mechanisms of Win32 or Qt.
- Objects maintain their own receive queues. Objects can migrate between contexts and a message can be sent to the object irrespective of what context it is executing in. In this situation queues are a bit like ports in the ROOM formalism.
- Message queues or “channels” as first-class objects. E.g. a queue for returning results might be passed via a message to a worker thread — when the worker thread completes it writes the result to the queue.
A few concrete use cases are:
- A pair of queues are used to communicate messages and results between a main (GUI) controller thread and an audio callback context. This is the primary communication architecture used in SuperCollider. It’s described in my book chapter here.
- Asynchronous disk i/o commands are sent to an i/o scheduler thread via a queue, each command specifies where the result of the i/o operation should be enqueued. This is somewhat similar to I/O Completion Ports.
- A thread receives audio data from a network socket and enqueues a packet record on a queue, the audio thread dequeues packet records and decodes them.
Implementation mechanisms (in brief)
There are a number implementation details that I won’t go in to detail about here, including: message implementation strategies, queue implementation, and delivery mechanisms. In the future maybe I’ll write about these in more detail. For now I’ll give a brief sketch:
Message implementations
A message queue transports messages from one execution context to another. A message is a bundle of parameters along with some kind of selector that specifies how the message should be interpreted or executed. In principle there might only be one type of message, in which case only the parameters need to be enqueued. However, a message queue often transports a heterogeneous set of messages, thus usually some kind of selector is needed. For example, something like the following struct, with an enumeration used to indicate the message type (this is similar to a Win32 MSG structure):
enum MessageCommandCode { DO_ACTION_1, DO_ACTION_2, DO_ACTION_3};
struct Message{
enum MessageCommandCode commandCode; // receiver interprets the command code
int messageData1;
bool messageData2;
}
Or a function pointer that is executed when the message is interpreted (this is the way SuperCollider does it for example, see my article about SuperCollider internals for more info):
struct Message{
CommandFunctionPtr commandFunc; // receiver calls the commandFunction passing the message and context-specific state
int messageData1;
bool messageData2;
}
You could do something more elaborate with C++11 lambdas, functors etc. But keep in mind that in a lock-free scenario you want to keep things simple and avoid overheads or allocations when sending messages.
An important thing to notice is that an enumerated command code can be interpreted in multiple ways (for example, by different states in a state machine) where as a function pointer can only be executed in one way (the latter case is more like code blocks in Apple’s Grand Central Dispatch). There are pros and cons of each approach.
For efficiency and to avoid blocking I recommend that the message is moved in to the queue when sending, and moved out of the queue when receiving — data is transferred by value. An optimization is to initialize/construct the message in-place in the queue buffer, rather than copying it there. Similarly, messages can be interpreted/executed directly from queue storage. The queue may support variable-length messages.
If you want your message data to be more expressive you could use a union or object with different sub-types for each message type.
Message could be implemented as polymorphic Command objects (cf. Command Design Pattern) although allocating and passing polymorphic objects in queues might get complicated. Depending on the number of commands involved, introducing polymorphic messages using virtual functions might just be overkill.
Messages might be timestamped and stored in a priority queue in the target context for future execution. Or messages might represent prioritized work (such as disk i/o) to be performed by the target context in priority order.
Ultimately there are many choices here. There are trade-offs between simplicity of implementation, ease of extension and complexity and readability of both the client code and the message passing infrastructure code.
See also: Command Pattern, Command queue, Message queue, message/command implementation in SuperCollider.
Queue implementations
This post focuses on situations where there is only ever a single-reader and single-writer to any queue. Partly this is because lock-free single-reader single-writer queues are relatively simple and efficient, and partly because they’re often all you need. That said, it is sometimes desirable or necessary to introduce multiple reader and/or multiple writer mechanisms: for example when a server thread has multiple clients sending it requests, or a single queue is used to distribute work to multiple worker threads. These cases can be implemented by using a lock at one end of a single-reader single-writer queue, or by using node-based lock-free queues such as the one by Michael and Scott.
Delivery mechanisms
The patterns in this post do not require or imply synchronous rendezvous or blocking/waiting when sending or receiving messages. A context might choose to block waiting for messages to arrive, or just as likely, it could poll the queue for new messages (without blocking) at certain synchronization points. Alternatively, some other mechanism might be used to ensure that the messages get processed. Some possible mechanisms are:
- An audio callback polls for messages at the start of each callback.
- A worker thread blocks waiting for an event/semaphore that is signaled when new messages are available.
- A GUI thread processes messages when it is notified that new messages are available (via a window system event)
- A GUI thread runs a periodic timer callback to update the GUI, the callback polls for new messages from another thread (without blocking)
- A consumer issues a get message whenever it finishes using a datum and processes received response messages whenever its local datum pool is exhausted.
Periodic polling is often criticized, and for good reason. Please keep in mind that in the cases above that employ polling, there is already a periodic task that is running for other reasons. For example to generate audio or update the GUI.
Now, on to the patterns…
The Patterns
1. Simple state management patterns
1.1 Mutate target state
One simple use for a command queue is to send messages that changes (mutates) some context-local state in the receiver. In the example below, a message is sent to change the colour of node x to red:
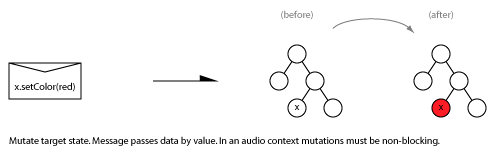
Note that the message is asynchronous. There is no locking involved because the data structure x is local to the right hand context. The x.setColor(red) code is executed in the right hand context. For comparison, the equivalent code in a lock based system might look like this:
// alternative implementation using locks
Node& x;
Mutex m; // protects x
// ... in context A:
m.lock();
x.setColor(red);
m.unlock();
// ... in context B:
m.lock();
... all operations on the structure and x must be protected by the mutex...
m.unlock();
One way to think about it is that in a lock-based system, the data comes to the code (context A gets access to object x), whereas in the message passing case the function call and parameters are sent to the data structure x in the receiving context (the function executes on context B). If context A and B are running on separate CPUs you can imagine different cache transfer patterns if x is accessed from context A, compared to passing a message (containing a selector, a reference to x, and the colour red) to context B where x is already in the CPU’s cache.
1.2 Get state vs Observer / state change notifications
In principle you could implement an asynchronous state request (”get”) message to asynchronously retrieve a state. This is a “pull” model:
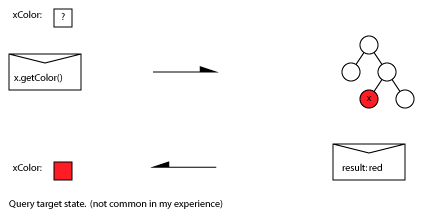
More likely you’d use some form of asynchronous Observer pattern where changes to x in the right hand context trigger change notification messages to be sent to the left hand context. This is a “push” model:
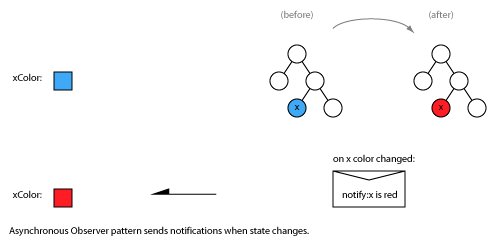
In the classical Observer pattern the receiver explicitly attaches/subscribes and detaches/unsubscribes from receiving notifications. For state that is constantly in flux (such as audio levels for VU meters) you might always post periodic notifications rather than requiring explicit subscription.
1.3 Synchronised state / cached state
Often, contexts operate in lock step, in the sense that a client knows (or categorically assumes) the state of the remote context. In this situation there is no need to explicitly request server state.
If there is a master/slave relationship between contexts/states the master can keep a local copy of the slave state — when the master needs to know the state of a slave it can synchronously query the local copy rather than sending an asynchronous message to the slave. Such mechanisms are akin to using a thread-local proxy cache with write-through semantics.
2. Generalized object transfer patterns
We assume shared memory, so transferring objects from one context to another requires only that an object pointer be passed in the message.
The generalized object transfer patterns below (Link, Unlink and Swap) deal only with transferring the visibility/availability of objects into or out of a context. They don’t say anything about the semantics of the transfer. For example they say nothing about whether the source context still references, manages, or owns the object after it has been transferred. More on that in a minute. First the patterns:
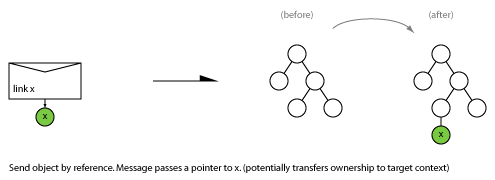
2.1 Link
Move an object from source to target. Install in target data structure.
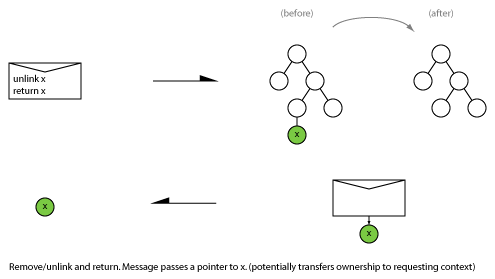
2.2 Unlink
Remove an object from a target data structure and return to source.
2.3 Swap/exchange
Replace an object in the target context with a new object. Return the old one.
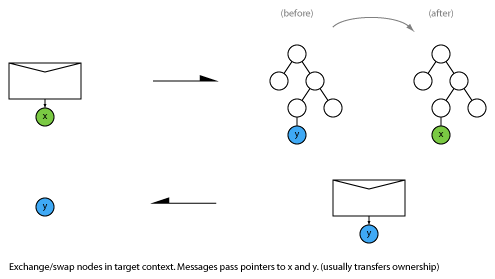
A new object is sent and installed in the receiver and the old object is returned. This mechanism can be used to implement atomic state update in O(1) time, even when the object is large or complex (such as a whole signal flow graph). It is related to using a double buffer or pointer-flip to quickly switch states.
Additional semantics for object transfer
It is often useful to overlay additional semantics on these object transfer operations. Potential semantics for object transfer include:
- Transferring between contexts transfers ownership. Objects are only ever accessed from one context at a time. The context that sees the object owns it and has exclusive access to it. Such objects need not be thread-safe.
- Transfer implies transfer of write access. Objects are only ever mutable in one context. Objects support single-writer multiple-reader semantics.
- Transfer implies “publication” of an immutable object. Objects are only mutable prior to publication to other contexts. Const methods need to be thread-safe.
- Transfer implies “publication” of a single-writer (possibly multiple-reader) object. Objects are only ever mutable in the source context. Objects support single-writer multiple-reader semantics.
- Transfer makes a thread-safe object visible to another context. Thread-safe objects are “Monitors” or multiple-writer safe. Their state and operations are protected by a mutex or other mechanism. They can be used concurrently from multiple contexts.
Semantics that enforce immutability, single-context access or a single-writer semantics can be useful because they can be used to avoid locks and blocking.
Note that things can get more interesting if you want to support these semantics and also allow the receiver to be destroyed prior to destroying the queue.
3. Object transfer patterns: allocation and deallocation in source context
In non-garbage-collected languages such as C and C++ you need to manage object lifetimes by explicitly allocating and deleting objects. Often this is handled by having strong ownership semantics: a specific object or process is always responsible for allocating and/or destroying particular objects.
In some contexts (such as a real-time audio callback) it is not appropriate to invoke the memory allocator at all, therefore allocation must be performed in another context.
The following allocation/deallocation pattern deals with these scenarios by allocating the new object in the source context when performing a link operation, and deallocating the result in the source context after performing an unlink operation.
3.1 Allocate in source context, link in target
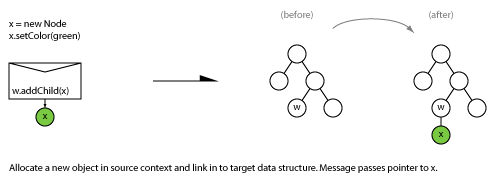
3.2 Unlink and return to in source context for destruction
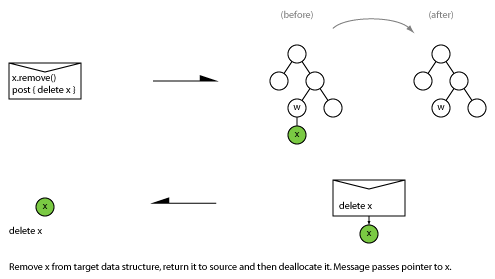
This pattern is useful when:
- Only the left hand side context can allocate memory (due to non-blocking requirements in the right hand context), AND/OR
- Allocating the object is time consuming or unbounded in time and the right hand context has strict time constraints.
The above example shows literal allocation and destruction of the object, but other variations are possible including:
- The object is allocated from and released to a pool that is local to the source context.
- Instead of allocating/destroying, a reference count is incremented/decremented in the source context on behalf of the destination. This means that the destination context always owns a reference count to the object, but it ensures that the final destruction of the object is always performed in the source context where it is safe to call the memory allocator or access other destruction-time resources.
4. Alternative allocation patterns
4.1 Context local storage/allocator/pool
Create new object and install in target context using destination-context-local storage:
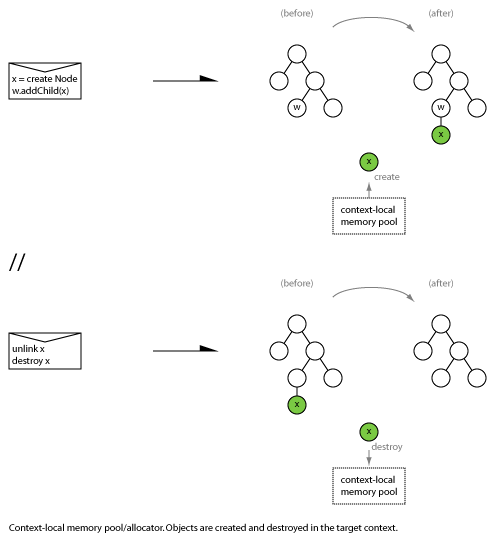
This pattern is useful when objects are always (or mostly) used locally in the receiving context, and allocation and deallocation can be implemented efficiently (e.g. using a simple freelist or O(1) allocator). There may be cache advantages to keeping objects local to a context. This pattern may also result in less complex memory management code in the receiving context if the objects are allocated and/or deallocated as the result of a number of different events, messages or state transitions.
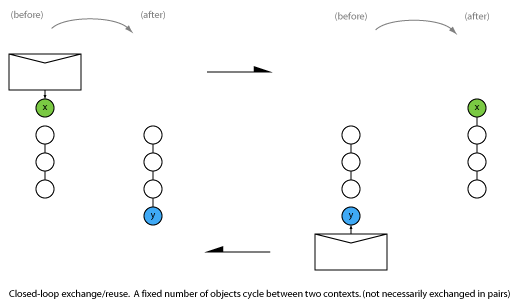
4.2 Closed-loop object reuse
Pre-allocating all needed resources is a common strategy for real-time memory management. Streaming systems usually have a known maximum number of buffers in-flight for a single stream. In these situations closed-loop circular buffer exchange can be used. A fixed number of objects is allocated and then cycled between contexts:
Conclusion
That’s it for the basic patterns.
As I said at the outset, this isn’t the whole picture. There are more involved patterns such as prioritized work lists, asynchronous state mirroring, and sub-object reference counting. You can implement transactions by combining messages so that a set of �state transitions is always executed atomically with respect to the receiver. You might want to limit the amount of allocated memory by only having a certain number of messages/objects in-flight at any time. Hopefully I’ll get around to writing about these mechanisms in future posts.
I hope these basic patterns and my explanations give you a new way to think about implementing asynchronous message passing communication in concurrent applications. If you know of any other patterns, references or links on this topic please share them in the comments.
