Asynchronous operations occur when we issue a request to perform an operation and receive the result of the operation at some later time. Operations might include reading data from a hard disk, or performing a calculation on another CPU core. I would like to be able to perform all actions related to managing asynchronous operations without blocking. Not only issuing requests and receiving responses, but also cancelling operations and aborting or terminating a session — even when asynchronous operations are in progress. In this post I describe some protocols and mechanisms for asynchronous cancellation, abort and clean-up that I have been experimenting with.
Cancellation is sometimes implemented as a blocking operation that can involve waiting for in-progress operations to complete. The mechanisms presented here never involve waiting, they provide completely non-blocking cancellation and abort using asynchronous message passing. The mechanisms relate to my previous posts about asynchronous message passing and patterns of message exchange. As in the earlier posts, the discussion is in the context of programs running in a shared memory space with asynchronous messages communicated between threads using queues.
Cancelling an asynchronous request
A client in one thread wants to send a message to ask a server in another thread to perform a long-running operation. The client expects to get a result back once the operation has completed. The result might be an object, or a value computed by the operation.
This process can be summarized as: (1) Client sends request to perform an operation; (2) Operation is performed in the server’s thread; (3) Client receives reply containing the result of the operation.

[Key: in these diagrams, client activity is shown on the left and server activity is shown on the right. Time progresses downwards. Half-headed arrows indicate asynchronous messages. Fat grey arrows indicate the flow of causality.]
The operation could take a long time to complete. It might take long enough that by the time it’s done the client no longer needs the result. To avoid unnecessary processing it would be nice to be able to cancel the operation. The client could send a message to request cancellation of the operation:
(1) Send request to perform an operation; (2) Request cancellation; (3) ??? now what?
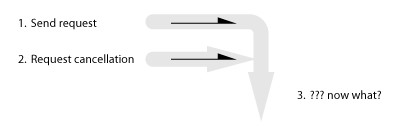
Here’s where things get interesting. Assuming that an in-progress operation can’t always be cancelled, there are four possible behaviors (including the no-cancellation case):
(i) Operation completes successfully. No cancellation. Client gets the successful result.
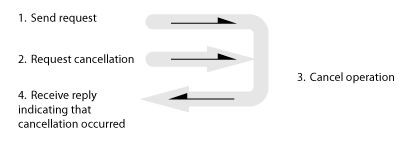
(ii) Cancellation succeeds. Client gets notified that the cancellation occurred.
(iii) Cancellation is attempted but fails. Client gets the result of the operation.
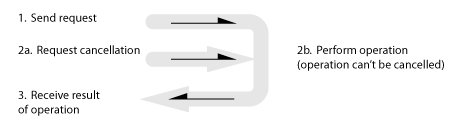
(iv) Cancellation is requested while the successful response is in flight on its way back to the client. Client gets the result of the operation. Cancellation request is ignored/dropped by the server.

In all four cases either the client receives back the result of the completed operation or a reply indicating that the request was cancelled.
Note that the cancellation request is advisory – the asynchronous nature of the message exchange means that the operation can’t always be cancelled. In case (iii) the operation wasn’t cancellable. In case (iv) by the time the server received the cancellation request the operation had already been completed and the result was on its way back to to the client.
Specifying which request to cancel
The server needs to know which request to cancel. In case (iv) above, the problem is to make sure that the delayed cancellation request is ignored and doesn’t accidentally cancel some other operation (e.g. a request from another client). We need a reliable mechanism for specifying which request to cancel. One that will work even when the original request has been completed.
Two mechanisms that won’t work are:
- We can’t request cancellation by specifying the parameters of the request (e.g. “cancel order for red paint”). What if another client has made the same request?
- Assuming that each request is an object, we can’t request cancellation by specifying a pointer to the request object. The problem is that in case (iv), the request object could be reused. Our cancellation request could then cancel a different operation. This is known as the ABA problem. Some programming APIs do use the request pointer to identify the request in a cancel operation (e.g. POSIX aio_cancel) but they tend to require that cancellation is a synchronous/blocking operation. We would like to perform cancellation asynchronously by sending an asynchronous cancellation request.
Three mechanisms that will work for identifying the request to cancel are:
- We could give every request a globally unique id and request cancellation by specifying the id. A naive way to do this would be to use a global counter that is incremented for every request. However that would create a bottleneck on a multiprocessor system.
- We could use the request object pointer plus a per-request serial number. The idea here is to construct unique request ids by combining the request object pointer with a counter that’s embedded in the request object. Each time the request is re-used the counter is incremented. This is similar to the ABA prevention mechanism used in some lock-free queues (e.g. Michael and Scott 96).
- Combining the previous two approaches, we could allocate a globally unique id to each client and combine that with a per-client sequence number to generate a unique request id.
Incidentally, mechanisms for uniquely identifying requests could also be used for performing other kinds of advisory modifications to a pending request. For example, to request a change to the priority of a pending operation.
Sidebar: requests that allocate and return resources
Some requests “allocate” and return a resource that needs to be “freed” by the client. I’m using quotes around allocate and freed here because really this applies to any operation on a resource that has paired lifetime operations. Other common paired operations include: open/close, lock/unlock, acquire/release, connect/disconnect, attach/detach and increment/decrement. Allocate and free are usually applied to blocks of memory. Another example would be opening and closing file handles: a request to open a file handle returns the file handle. When the client is finished with the file handle the file handle must be closed by sending a request to close the file handle.
Requests that allocate and return resources should have clear cleanup semantics. In a garbage collected environment cleanup might be a no-op. More commonly there will be an “inverse” operation to release an allocated resource. For example, when a client requests an object and receives it, the client should eventually release the object by posting it back to the originator.
Forgetting about cancellation for a moment, the message exchange looks like this:
(1) Send request; (2) Perform operation/allocate resource; (3) receive result of operation/resource; (4) Send resource back to originator to be released; (5) release resource.
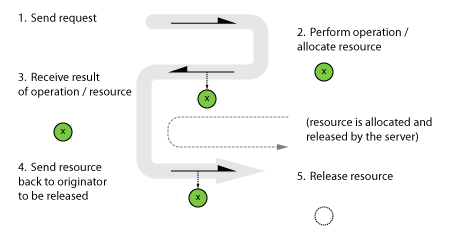
(See an earlier post for examples of asynchronous message patterns that pass around objects using matched alloc/free message exchanges.)
It’s a common pattern to release a resource by returning it to the originator. For the purposes of the following discussion it’s not necessary to require return-to-originator semantics. Any clean-up operation will do (decrementing a reference count or freeing a resource to a global allocator are other possibilities).
Cancelling requests that allocate and return resources
Earlier we considered a mechanism for requesting an asynchronous operation and for cancelling it. Now assume that the operation returns a resource that needs to be released. What if we would like the client to be able to cancel the request?
Assuming that the client is going to be around to handle the reply when it eventually arrives, the process is straight forward: send a cancellation request, if the reply arrives clean up the resource immediately, if the cancellation succeeded there’s nothing special to do. There are two other cancellation use-cases that are more interesting. I’m going to call them “Reset” and “Abort”:
- Reset: the client is no longer interested in replies to its previously issued requests and wants to effectively ignore replies when they arrive. The client will be present to receive the replies.
- Abort: the client is no longer interested in replies to its previously issued requests and won’t be available to receive the replies. For example, the client might have been deleted. In this case a mechanism is needed that doesn’t try to deliver replies to the non-existent client.
In both cases our goal is clear: (1) Send request; (2) Reset or Abort.

The client can request cancellation: (1) Send request; (2) Request cancellation; (3) Reset or Abort.

But as we saw in case (iv) above, the operation could still complete successfully and send back a resource that would need to be released. To remind you, here’s case (iv) again:
(iv) Cancellation is requested while the successful response is in flight on its way back to the client. Client gets the result of the operation. Cancellation request is ignored/dropped by the server.
To implement a “Reset” we need to arrange to immediately clean up the response when the client receives it. In the “abort” case the client won’t be available to receive the response. Given what I’ve presented so far the best we could do is cancel any pending requests and then wait for them to complete. In pseudocode:
Non-solution: Send request → Request cancellation → Wait for request to complete. Receive reply with object or cancelled status ← If request completed successfully: Send resource back to server to be freed → Reset or Abort
The problem with this approach is that we are proposing to wait. Waiting is not part of the plan, remember:
I’m going to present two possible solutions: one for the “reset” case and one for the “abort” case.
Wait-free “reset” using client-side session ids
Recall that a “reset” involves ignoring responses to any requests that were made before the reset point. The client will be around to receive responses, but we want it to ignore some of them. The client must correctly clean-up any resources associated with the ignored replies. To do this we can use the following mechanism:
Algorithm: Each client maintains a unique integer value for the current session. This “session id” is stored in each request and is returned by the server in the corresponding reply. When a client receives a reply, the reply’s session id is compared with the client’s session id. If the values match, the reply is processed normally. If the values don’t match then any resources contained in the reply are cleaned up immediately. Any time we want to “reset” a client we simply increment the client’s session id. From that point on, whenever the client receives a reply to a request issued before the “reset”, the reply will be cleaned up straight away. In pseudocode:
Do reset: Request cancellation of any pending requests → Clean up any resources we're holding: Send resources back to the server to be freed→ Increment client.sessionId On receipt of a reply: if reply.sessionId == client.sessionId: handle reply else: Clean-up any resources in the reply: Send resources back to the server to be freed→
This algorithm works so long as the client is around to receive all of the replies. It even handles multiple resets.
Wait-free “abort” using asynchronous mailbox clean-up
Recall that an “abort” entails the case where the client will no longer be present to process replies. For example, the client is deleted immediately after aborting.
I haven’t mentioned mailboxes so far, but in an asynchronous message passing system they are implied. Messages are asynchronous. They need to be queued somewhere before they are received. In a previous post I described using FIFO queues for this purpose:
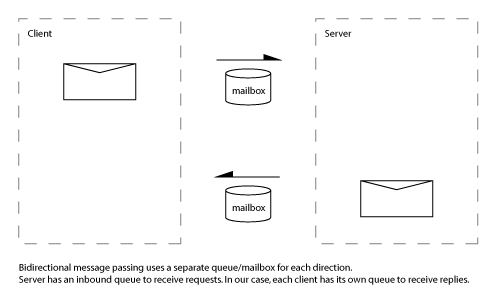
There are different ways to set up a mailbox queue. The mailbox might belong to a thread, or to a dispatcher. In the mechanism I’m going to describe, every client has its own mailbox. This isn’t always appropriate, but it supports my solution to aborting while requests are in-flight. Since every client has their own mailbox we get some other technical benefits: the mailbox is not tied to a particular thread of execution, which means that client objects are not tied to a per-thread dispatcher, and, assuming a single server, the mailbox can be “single reader single writer” since only the server writes to it, and only one client reads from it.
There are a couple of pre-requisites for the mechanism that I’m going to describe next:
- There is a single remote entity (server) to whom the client sends requests and from whom the client receives replies containing resources.
- The client receives replies in an exclusive client-owned mailbox.
To recap, we’re trying to resolve the problem where replies get sent to the client after the client has aborted and/or been deleted. The problem can be summarized as: (1) Send request; (2) Request cancellation; (3) Abort somehow; delete client; *crash*
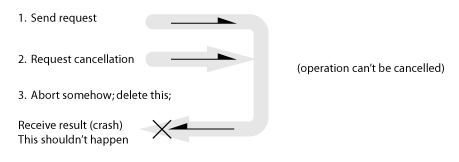
The problem is twofold: the client is not present to receive and process the reply, and the reply contains resources that need to be released. We would like the client to be able to completely drop all responsibility for dealing with responses to any in flight replies. Sending a cancel request is not sufficient. The replies need to be handled otherwise resources will leak.
Here’s my solution:
(1) Send request; (2) Request cancellation; (3) Send mailbox to server for cleanup; (4) Server delivers result / resource to mailbox; (5) Server cleans up mailbox.
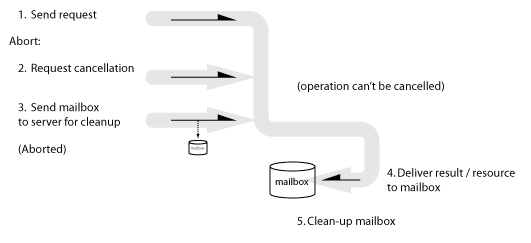
In pseudocode:
(client) Request → Abort: Request cancellation of any pending requests → Send mailbox to server for clean-up → Abort. (server) → Receive mailbox for clean-up Until all replies have been received: Clean-up replies/resources in Mailbox
The idea is to make the server responsible for cleaning-up and freeing any replies that the client hasn’t handled. In fact the server never talks directly to the client. Communication is always mediated by the mailbox. When the client aborts (and is possibly deleted) the mailbox is “torn off” and returned to the server for cleanup. When the mailbox is received by the server for clean-up the server frees any objects it finds in the mailbox.
I’ve included cancellation requests in the algorithm but they’re not strictly necessary. In some cases they are useful to avoid unnecessary operations from being performed.
Since the server is responsible for sending replies, it’s fair to assume that we can devise a server-side clean-up mechanism that polls the mailbox to implement the “until” clause without blocking. I won’t discuss that in depth since it depends on the mechanism that the server uses to process requests and dispatch replies. A simple mechanism would be for the server to maintain a list of mailboxes to clean-up and to poll each of them for completion each time a request is processed.
The server needs a method to determine when all pending replies have been delivered to a mailbox. That’s the final piece of the puzzle.
Server needs to know when a mailbox has quiesced
When a server receives a mailbox for clean-up it can immediately process all of the replies that are in the mailbox. However, before the server can dispose of a mailbox it needs to be sure that no further replies will be queued in the mailbox. There should be no possibility of a reply being placed in a mailbox after it has been disposed.
In the simplest case, when a mailbox is empty and there are no pending requests then we can conclude that all replies have been received and cleaned up. In a concurrent, asynchronous scenario, additional requests might not yet have arrived, or replies might not yet have been issued (requests could have been reordered, or the server might have queued replies internally waiting for asynchronous operations to complete). To handle these cases:
Algorithm: Every time the client issues a request for which it expects a reply, the client increments a “reply expected” counter field in the mailbox. When a reply is collected from the mailbox, the counter is decremented. When the server is cleaning up a mailbox it performs the appropriate decrements on the counter as it cleans up each reply. When the counter falls to zero, the server knows that the mailbox can be disposed.
In order to correctly increment the reply-expected counter when the message is being sent, the client must be able to determine whether the message will have a reply. Similarly, the server needs to know which replies/messages should cause the counter to be decremented. This suggests that either a request has a reply or it doesn’t. Optional replies can’t be accommodated — the server wouldn’t know when it was safe to dispose the mailbox.
Sending mailboxes to the server for asynchronous clean-up supports the “abort” use case. This allows clients to abort without waiting for replies to their pending requests. One case where this is useful is when it is desirable to delete a client immediately.
Note that the mailbox-posting abort cleanup mechanism is optional. Clients can re-use mailboxes, or share mailboxes so long as they perform their own clean-up before disposing the mailboxes. It’s only when the mailbox is expecting results and there is no client left to check the mailbox that the abort mechanism is needed.
Close
The mechanisms described here can be used to provide wait-free cancellation and abort while communicating with asynchronous server threads. The mechanisms support requests that allocate and return resources that need to be released. I described a mechanism for non-blocking cancellation, and a mechanism for immediate abort with safe resource clean-up. The mechanisms don’t require any special client-side dispatcher or scheduling mechanism. The wait-free abort does require each client to have its own mailbox – this can be an advantage since it allows the client to move between threads without a complex per-thread event dispatch mechanism.
Thanks for reading.
If you’ve seen these or other related mechanisms in the literature or in the wild I’d love to hear from you. Please post in the comments, ping me on twitter @RossBencina, or drop me a line at rossb@audiomulch.com.
