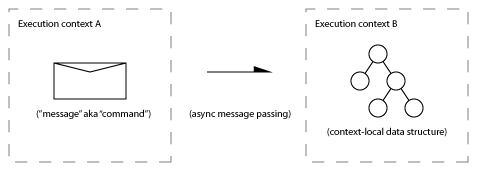
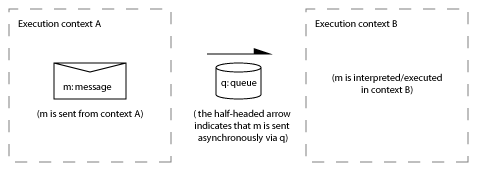
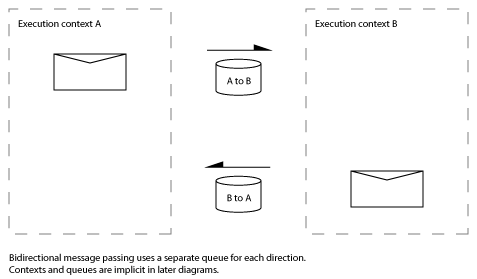
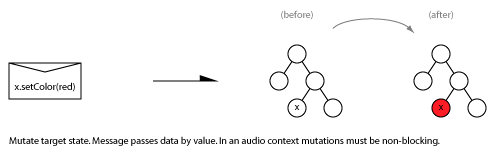
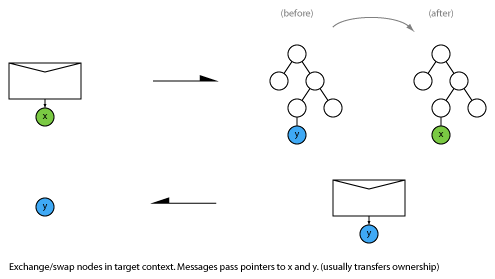
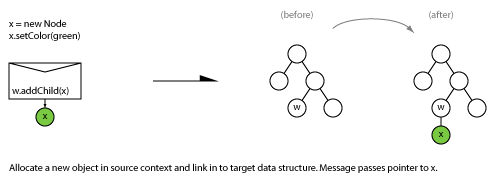
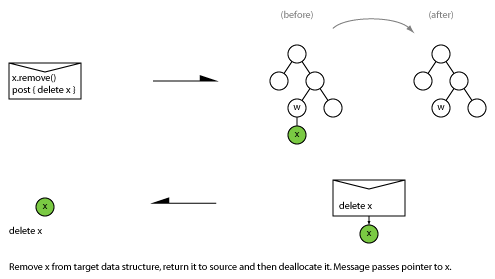
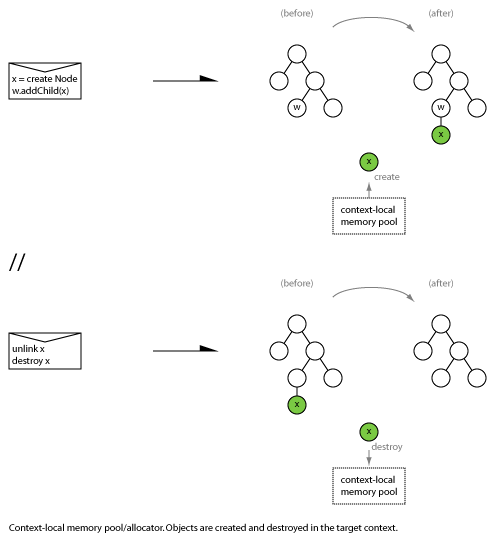
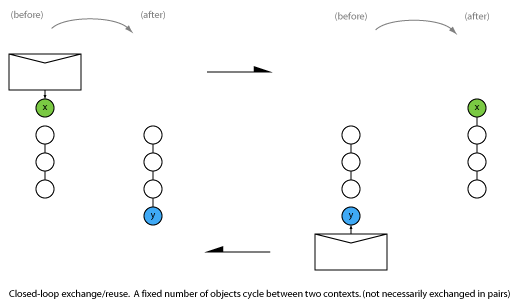
When two parties communicate, what are the possible patterns of message exchange?
Here’s what I’ve come up with so far:
(Updated June 22, 2013 with causality arrows, failure modes, sequences and reordering, streams, non-deterministic communication.)
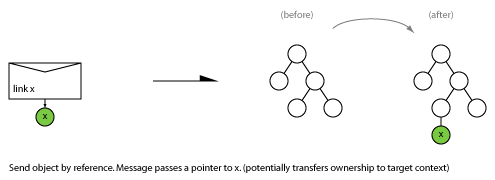
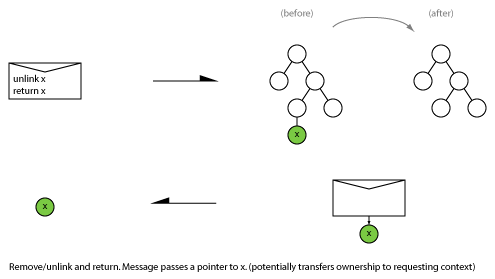
Send

Also known as: procedure call, one-way, unidirectional, post, fire and forget, In-Only, Out-Only, request (R), trigger, event, notification, command, producer-consumer.
At this level “sending a message” is the ultimate primitive (although it decomposes into: prepare, post, transport, deliver, receive).
Send failure modes


Also known as: unreliable transport.
A message may fail to be delivered, or the receiver may fail to process it (either intentionally or unintentionally). Sometimes message transport and processing is guaranteed to be reliable and these failure modes don’t arise.
Sequence (in order, out of order)
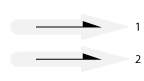

Order of arrival may or may not be guaranteed.
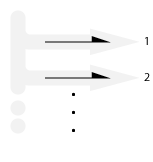
Stream
Infinite stream:
Finite stream:
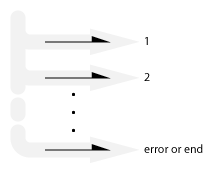
Also known as: Rx IObserver protocol.
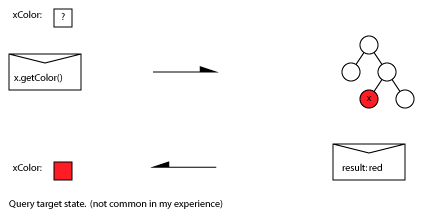
Request-Reply

Also known as: function call, round-trip, request/response (RR), In-Out, Out-In, call-response, request-result, remote procedure call, polling, solicit-response, query-response.
The reply may provide useful information, or simply acknowledge receipt of the request. The reply might be optional (“In Optional-Out”). Spector (1982) also considers the three message exchange: request/response/acknowledge-response (RRA) . This may not be necessary when message transport is reliable.
Request-Multi-reply
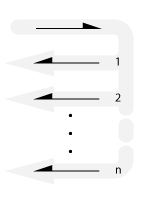
A single request results in a number of reply messages.
Also known as: progress callback.
Each reply reflects a phase of a progressive process.
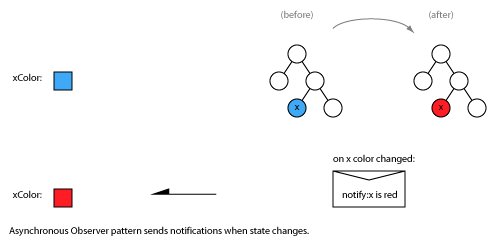
Subscribe-Notify
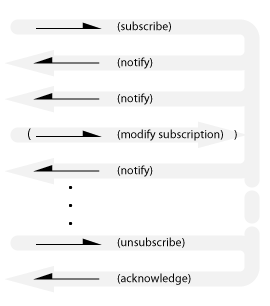
Also known as: observer, periodic timer, streaming updates, event driven, Hollywood principle.
Note that this is not the same as the multi-point publish-subscribe distribution pattern.
The final acknowledgement is required for the subscriber to be sure that it won’t receive any further notifications.
An implicit subscription variant exists where notifications are sent without the client subscribing (like spam). Maybe that’s called Advertising.
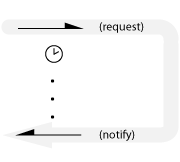
One-shot notification
Normal case:
Canceled case:
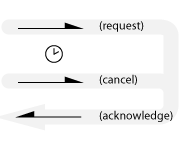
Also known as: one-shot timer, delay, asynchronous completion notification, future, cancelable-future, callback.
Non-deterministic communication

If both parties simultaneously send a message to the other there can’t be any guarantee about the order of arrival at each site. For example, a cancellation message could be sent while a notification is already in-flight, as shown below.
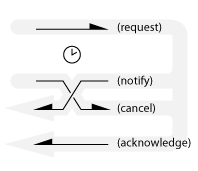
?
Do you know other patterns? Let us know in the comments.
What’s this?
I’m musing about message exchange patterns. Specifically, those relevant to reliable asynchronous message exchange between two threads in a concurrent shared memory system. I wrote this in an attempt to abstract the message exchange aspect of this post. I’ve focused here on message exchange events, ignoring the details of the items being exchanged. When you also consider the items being exchanged, higher-level patterns emerge (consider juggling patterns for example).
There are many areas of computing that study or use message exchange. They include: protocol design, real-time systems, distributed computing, SOAP MEP, MPI, bus communication protocols, and process calculi. I am not an expert in these fields but I am interested in what they can teach me about message exchange. There are some links to related resources at the end.
Additional reflections
Acknowledged assumptions
I have assumed that the two parties outlive the message exchange.
I have assumed that the two parties know how to address messages to each other — although often it is enough that the requestor know the address of the respondent, since the requestor can provide a return address to the respondent as part of the request.
Conversations
Request-Reply, Request-Multi-reply and/or Send sequences can be concatenated to form longer back-and-forth conversations. Certain transactions such as two and three-phase commit require multiple request-reply pairs.
Symmetry/asymmetry
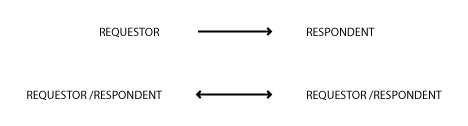
The relationship between endpoints may be symmetric: either party may be the initiator in the above exchanges; or asymmetric (as in master-slave, client-server relationships etc.).
WCF has a related concept called Service Contracts. WCF defines three types: Request-Reply, One-Way and Duplex.
Party visibility
Does the receiver know the identity of the sender? Does the message provide this information?
A reply is only possible if the receiver knows the sender’s identity. Sender could provide a return address, or receiver may already know the address. Are sender and receiver knowing participants in a fixed (or dynamic) topology? Does receiver retain or store sender’s identity? When does receiver need to do this? (Subscriptions are one case.)
Message bus architectures distribute events to subscribers without the sender knowing the identity of the receiver. Anonymizing servers provide a route between requestor and respondent without revealing the identity of the requestor to the respondent.
Message semantics
Some writers (eg. Spector 1982) are concerned with efficient and minimal primitives for message transport. SOAP Message Exchange Patterns are similarly concerned with mechanism.
You can also consider the purpose or role of a message. For example, a unidirectional message may be a command to perform an action, or it may be a notification that something has happened. Notifications can be further subdivided into those provided for informational purposes (“last lap of the race”) and those that require action (“evacuate now”).
This post from i8c on Basic Message Exchange Patterns makes an argument for considering more expressive patterns that capture the abstract purpose of a message exchange. It lists 10 communication patterns from SAP, broken into two layers: service communication patterns (query/response, request/confirmation, information, notification) and transaction communication patterns (information, notification, query, response, request, confirmation).
This article on Messaging Patterns in Service-Oriented Architecture also presents “higher level” patterns. For example, when considering unidirectional messages it distinguishes between Command messages, Event messages (notifications) and Document messages (information transfer).
Consider the difference between a command (sent with intent) and an event/notification (interpreted by the receiver).
Also consider command-query separation (and here).
Reactive vs. dataflow
Some message passing systems are concerned with managing the flow of data between processors in a computation (eg. HPC systems based on MPI), whereas others are concerned with reacting to external events or processing transactions (eg. operating system kernels, interactive systems).
Stateful vs. stateless protocols
By focusing on message exchange I have sidestepped the perspective of stateful protocols. Stateful protocols are (usually?) modeled as communicating state machines. Messages drive state transitions and the current state determines which messages are legal. (Searching for “communicating state machines” is a good place to start reading about this.)
Non-software processes
I am interested in applying these patterns to messages passed between communicating computer programs, but the patterns appear in the real world too. Real-world examples include: sending a postcard, an exchange of letters in a legal or bureaucratic process, patterns of business communication, types of business transactions, subscribing to a periodical, marketing email workflows, customer service processes, and so on.
Am I missing something?
Please let me know in the comments if you can think of other patterns, book recommendations, good links or a more abstract (domain-neutral) treatment of this material.
I tried the following searches. Can you suggest other keywords or terms I have overlooked?
communication patterns | two party communication patterns | service communication patterns | transaction communication patterns | message passing theory | message exchange | message exchange theory | packet exchange theory | message exchange protocols | two party message exchange protocols | message communication theory | event driven patterns | event interaction ontology | event exchange patterns
Responses from the Twitterverse
Here are the suggestions for additional message exchange patterns that I’ve received so far (updated January 9, 2013):
Alex McLean @yaxu tweets:
how about scissors-paper-stone voting?
Me: good one. how to draw the picture? +not sure of utility since it is either biased (w/ defaults on ties) or non-wait-free (w/ retries)
on further thought it’s just a request-reply unless you have shared memory, in which case it’s not a message exchange.
reqest/reply: A proposes game along with “sealed” vote, B replies with it’s vote, then opens the seal. B must be honest.The replies should be simultaneous though / or be received/processed after they’ve all been sent.
There may be similar constraints around time sync protocols.. E.g. data not in the message but in time between send and replyMe: Indeed time sync protocols are something to consider. As for rock-paper-scissors and timing: www.youtube.com/watch?v=3nxjjztQKtY …
Yeah that’s related to Thor’s diplomatic reading between the lines too.ok how about DNA message that creates a third party?
thor magnusson @thormagnusson tweets:
Also: communication based on not willing to communicate: ignoring messages & breaking protocols. (Eg. Middle east & N-irland)
Also, Austin’s book “How to Do Things with Words” on speech acts, might be an interesting read. (BTW good #openresearch!)
Damian Stewart @damian0815 tweets:
Telephone pictionary. It’s just unreliable Send, but after several transmissions the unreliability becomes the message.
See also
My Interaction Diagrams board on pinterest.
Background reading (for you and me)
Transport level
- Alfred Z. Spector. 1982. Performing remote operations efficiently on a local computer network. Commun. ACM 25, 4 (April 1982), 246-260. www.cs.tufts.edu/~nr/comp150fp/archive/alfred-spector/spector82cacm.pdf
Programming models
- Message Passing Concurrency at c2.com c2.com/cgi/wiki?MessagePassingConcurrency
- Futures and promises en.wikipedia.org/wiki/Futures_and_promises
- Promise pipelining c2.com/cgi/wiki?PromisePipelining
- Gregor Hohpe, “Programming Without a Call Stack – Event-driven Architectures,” www.eaipatterns.com/docs/EDA.pdf
- Event driven architecture en.wikipedia.org/wiki/Event-driven_architecture
- M. Broy , R. Grosu , C. Klein, “Reconciling Real-Time with Asynchronous Message Passing (1997)”, FME’97 Proceedings. citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.41.5268
- Reactive Extensions (Rx) reactive stream processing. See also this question at Stack Overflow.
Operating systems
- A “Packet” History of Message-passing Systems www.netlib.org/utk/lsi/pcwLSI/text/node58.html
- QNX Asynchronous Messaging www.qnx.com/developers/docs/6.4.1/neutrino/technotes/async_messaging.html www.qnx.com/developers/docs/6.4.1/neutrino/getting_started/s1_msg.html
- OSDev Message Passing (for Microkernel implementation) wiki.osdev.org/Message_Passing
Enterprise, SOA, SOAP, EIP
- Messaging pattern en.wikipedia.org/wiki/Messaging_pattern
- Enterprise Integration Patterns www.eaipatterns.com/toc.htmlcamel.apache.org/enterprise-integration-patterns.html
- W3C Web Services Message Exchange Patterns www.w3.org/2002/ws/cg/2/07/meps.html
- Better Message Exchange Patterns integr8consulting.blogspot.com.au/2011/04/better-message-exchange-patterns.html“Bottom line: there are better ways to categorize service patterns, independent of the actual technical implementation.”
- SAP Communication Pattern help.sap.com/esoa_tm60/helpdata/en/b7/8d32bdca2a4f6e9840f0d84a763ad6/content.htm www.sdn.sap.com/irj/scn/go/portal/prtroot/docs/library/uuid/303856cd-c81a-2c10-66bf-a4af539b8a3e?overridelayout=true
- SOA, EDA, and MPI.NET bill-poole.blogspot.com.au/2008/10/soa-eda-and-mpinet.html
- Messaging Patterns in Service-Oriented Architecture msdn.microsoft.com/en-us/library/aa480027.aspx
- Understanding Message Exchange Patterns of an Oracle Mediator docs.oracle.com/cd/E21764_01/integration.1111/e10224/med_interactions.htm
- TIBCO Event-Driven Interaction Patterns my.safaribooksonline.com/book/software-engineering-and-development/soa/9780132762427/design-patterns-with-tibco-activematrix/ch12
- Message Oriented Design Patterns for SOAP Services www.designpatternsfor.net/Presentations/MessagingOrientedDesignPatternsForSOAPServices.pdf
- BizTalk Server: Standard Message Exchange Patterns and Types of Service www.packtpub.com/article/biztalk-server-standard-message-exchange-patterns-service-types
- Extending the WCF Channel Layer: Six Message Exchange Patterns
MPI
- MPI Collective Patterns (Broadcast, Scatter/Gather, All gather, All to All) www.mcs.anl.gov/research/projects/mpi/tutorial/gropp/node74.html#Node74
- Xiaohong Qiu, Geoffrey Fox, H. Yuan, Seung-Hee Bae, George Chrysanthakopoulos, and Henrik Frystyk Nielsen, “High Performance Multi-Paradigm Messaging Runtime Integrating Grids and Multicore Systems”, Proceedings of eScience 2007 Conference, Bangalore India, Dec. 2007 [[MPI multithread patterns]] salsahpc.indiana.edu/content/high-performance-multi-paradigm-messaging-runtime-integrating-grids-and-multicore-systems
Interaction ontology
- Gerrit Niezen, “Ontologies for interaction: enabling serendipitous interoperability in smart environments” PhD TU/e repository.tue.nl/735539 [pdf]
Communication theory
This is getting a bit lateral, but it might be useful…
- Communication theory en.wikipedia.org/wiki/Communication_theory
- Models of communication en.wikipedia.org/wiki/Models_of_communication
- Communication Models www.shkaminski.com/Classes/Handouts/Communication%20Models.htm
Thanks for reading!