With your friendly host Ross Bencina and friends from the #musicdsp optimisation laboratory.
Introduction
I’ve liked sinusoids for a long time. This is a place where I’m going to write about them.
This page initially came about while investigating efficient implementations of Ollie Niemitalo’s parabolic sin(x) approximation (see below.) At the moment it’s a bit disorganised, but perhaps you will find something of interest here.
Performance Measurement Methodology
The perfomance measurements shown below were conducted under strict unscientific conditions with no third-party validation at our secret labs in Tierra Del Fuego. The measurements are stated in machine cycles and were performed with MSVC on a PIII/550.
Approximations
There are quite a few ways to approximate sinusoids: Taylor polynomials, CORDIC, iterative methods, lookup tables, just to name a few. I’m building up a catalog of some of these below. It’s not finished yet.
Joakim Dahlström has kindly contributed a Java applet which allows you to visually explore various sinusoidal approximations and their parameters.
Look Up Tables (LUTs)
Look-up tables are commonly used for generating all sorts of functions which are expensive to calculate on the fly. The general idea is that values are pre-calculated and stored in an array so they can be “looked up” later. In this case we are concerned with storing values of sin(x) in a lookup table.
Variants on the look up table use interpolation to approximate values “in the gaps” between the values stored in the table. The simplest form of interpolation is linear interpolation, which interpolates along a line between adjacent points.
Both the size of the lookup table, and the method of interpolation effect the quality of the approximation. Below are the spectra of sine waves generated using look up tables of different table sizes with no interpolation and with linear interpolation.

128 point lookup table, no interpolation
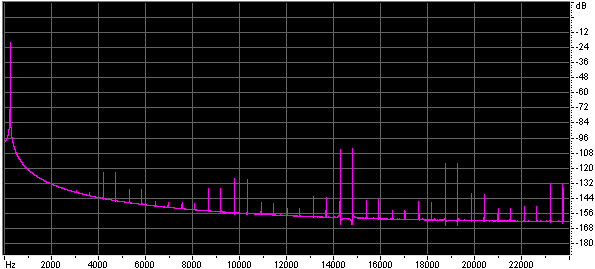
128 point lookup table, linear interpolation

2048 point lookup table, no interpolation

2048 point lookup table, linear interpolation

64k loopup table, no interpolation
listen to a short melody synthesized using this approximation (22k mp3 file)

64k lookup table, linear interpolation
Below are some wave files of sine waves generated using very short lookup tables, each file is 45k. You might find it interesting to look at them in a wave editor.
- 4 point lookup table, no interpolation
- 4 point lookup table, linear interpolation
- 8 point lookup table, no interpolation
- 8 point lookup table, linear interpolation
- 16 point lookup table, no interpolation
- 16 point lookup table, linear interpolation
- 32 point lookup table, no interpolation
- 32 point lookup table, linear interpolation
- 64 point lookup table, no interpolation
- 64 point lookup table, linear interpolation
An implementation of approximate_sin(x) using a non-interpolated 64k lookup table took 90 cycles.
An Optimized LUT Implementation
Oskari Tammelin contributed the following i86 assembley optimised LUT implementation which can be used for synthesizing sine waves, or any other waveform.
looppi:
mov edi, esi
shr edi, (32 - LUT_BITS)
mov edx, esi
and edx, (1 << (32 - LUT_BITS)) - 1;
mov eax, Lut[edi*8+4]
imul edx
add esi, ecx
add edx, Lut[edi*8]
mov edi, esi
mov [ebp], edx
shr edi, (32 - LUT_BITS)
mov edx, esi
and edx, (1 << (32 - LUT_BITS)) - 1;
mov eax, Lut[edi*8+4]
imul edx
add ebp, 8
add edx, Lut[edi*8]
add esi, ecx
mov [ebp-4], edx
cmp ebp, [esp]
jnz looppi
Oskari provided the following explanation (slightly edited):
esi is the phase, ebp the output pointer
The LUT should contain one cycle of a sinewave, interleaved with the delta between adjacent points ([x+1] – x[i]) to make linear interpolation easier. The deltas in the table must be scaled by number of samples in the LUT because edx for the imul is taken from the lower part of the phase in order to save one shl.
It calculates two samples per iteration and executes in approximately 7.8 cycles / sample.
An Optimised LUT in C
Magnus Jonsson contributed the following code:
#define PI 3.1415926535897932384626433832795
#define TABLE_BITS 8
#define TABLE_SIZE (1<<TABLE_BITS)
#define TABLE_SIZE2 (2<<TABLE_BITS)
float table[TABLE_SIZE+1];
void init_table()
{
for(int i=0;i<TABLE_SIZE;i++){
double x=(double)i/(TABLE_SIZE-1);
double y=PI/2;
if(i!=0)
y=sin(x*y)/x;
table[i]=y*1.0/65536.0/65536.0;
}
}
float zael_sin4(unsigned x)
{
unsigned a=-((unsigned)x>>31);
x+=x;
unsigned b=-((unsigned)x>>31);
x^=b;
float scale=table[x>>31-TABLE_BITS];
x^=a;
return (int)x*scale;
}
Piecewise Polynomial Approximation
Ollie Niemitalo has presented a method of approximating sinusoids using piecewise parabolic approximations of sin(x) here: www.dspguru.com/comp.dsp/tricks/alg/sincos.htm . Olli’s algorithm using C=0.75 provides a continuous first order derivative resulting in harmonics which decay at a rate of -18dB per octave.
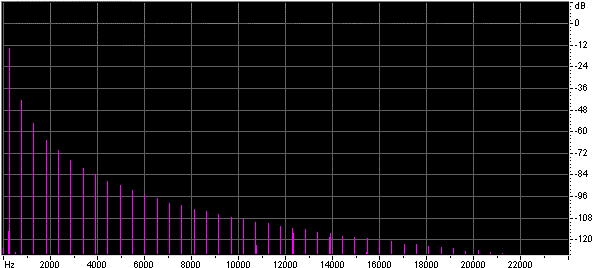
This is the spectrum of a signal generated using Olli’s approximation with C=0.75.
Click here to listen to a short melody synthesized using this approximation (22k mp3 file) If you compare this soundfile with the 64k table lookup approximation above you should be able to hear that the presence of harmonics produces a less ‘pure’ tone.

This graph shows the first quadrant of sin(x) and Ollie’s approximation with C=0.75. The upper curve is the approximation the lower curve is sin(x).
(Almost) Branch-Free Integer Implementation
Below is my (almost) branch-free integer implementation based on Ollie’s. It’s worth noting that Ollie’s can produce sin(x)/cos(x) at the same time – I havn’t got around to implementing that yet. For some reason this implementation has a much higher noise floor that the other contributions below, you would probably be better off using one of them.
This version takes 37 cycles not including the if( x == 0 ) conditional.
/*
approximate_cos() by Ross Bencina <rossb@audiomulch.com>
based on Olli Niemitalo's <oniemita@mail.student.oulu.fi>
parabolic sin and cos implementation, available here:
http://www.dspguru.com/comp.dsp/tricks/alg/sincos.htm
this version is a variation on Olli's which uses no branches and
hence may be able to run faster on some pipelined architectures.
input range: a 32 bit unsigned long, 0 => 0, 0xFFFFFFFF => 2 Pi
output range: a 32 bit unsigned long -1 => 0, 1 => 0xFFFFFFFF
this version currently generates the incorrect value for x=0
if you work out how to fix it without slowing the code down
please let me know.
*/
unsigned long approximate_cos( unsigned long x )
{
unsigned long i,j,k;
if( x == 0 )
return 0xFFFFFFFF;
i = x << 1; // 2f phasor (full unsigned amp)
k = ((x + 0xBFFFFFFD) & 0x80000000) >> 30; // 1f square 270 degrees out of phase, 0 to 2
j = i - i * ((i & 0x80000000)>>30); // 2f triangle
j = j >> 15;
j = (j * j + j) >> 1; // polynomial shaping into |sin|
j = j - j * k; // switch phase of second half
return j;
}
i86 Assembley Version
Ollie contributed this i86 assembler version which executes in 14 cycles.
mov EAX, phase //EAX = 32-bit phase add EAX, EAX //Carry = the half bit, EAX = phase within half sbb EBX, EBX //EBX = 0 if left half, -1 if right half sub EAX, 80000000h //Shift phase by a quarter imul EAX //EDX = 0..40000000h sub EBX, 80000000h //EBX = -80000000h if left half, +7fffffffh if right lea EAX, [0c0000000h+EDX] //Add bias to the parabola imul EBX //Change sign if necessary mov result, EDX //Result = sine approximation -20000000h..+1fffffffh
And the shortest assembler version so far, 5 instructions:
mov EBX, phase //EBX = 32-bit phase lea EAX, [80000000h+EBX*2] //Take phase within half, shift by 1/4 sar EBX, 31 //Get sign imul EAX //EDX = 0..40000000h lea EAX, [80000000h+EDX*2] //Add bias to the parabola xor EAX, EBX //Change sign if necessary mov result, EAX //Result = -80000000h..7fffffffh
16 bit Branch Free Implementation
Lauri Viitanen has provided a C language 16 bit branch free version of Ollie’s algorithm that computes sine and cosine terms simultaneously. Written in C (GPLed), it’s here: fastSinCos16.c
Floating-Point Implementation
René Ceballos contributed the following pure floating point implementation of Olli’s approximation with C=0.75.
This version takes 62 cycles.
/*
approximate_sin() by René G. Ceballos <rene@rgcaudio.com>
input range: 0.0 to 2.0 * Pi
output range: -1.0 to 1.0
*/
float approximate_sin( float angle )
{
const float k2_oPi = 2.f / Pi;
const float k2Pi = Pi2;
const float kPi_2 = Pi / 2;
const float kPi = Pi;
const float kPi_32 = 3 * Pi / 2;
float x,j;
if( angle < kPi_2 ){
x = angle * k2_oPi - 0.5f;
j = -(x * x) + 0.75f + x;
}else if( angle < kPi ){
angle = kPi - angle;
x = angle * k2_oPi - 0.5f;
j = -(x * x) + 0.75f + x;
}else if( angle < kPi_32 ){
angle -= Pi;
x = angle * k2_oPi - 0.5f;
j = x * x - 0.75f - x;
}else{
angle = k2Pi - angle;
x = angle * k2_oPi - 0.5f;
j = x * x - 0.75f - x;
}
return j;
}
Another Branch Free Integer Approximation
The following four sinusoidal approximation implementations were contributed by Magnus Jonsson. They are based on the same parabolic approximation as Olli’s but were derived independently.
The first C version takes 42 cycles.
/*
approximate_sin() by Magnus Jonsson <zeal@snuttis.com>
input range: full unsigned 32 bit( 0x00000000 to 0xFFFFFFFF )
output range: full signed 32 bit ( -0x7FFFFFFF to +0x80000000 )
*/
int approximate_sin1(unsigned x)
{
unsigned s=-int(x>>31);
x+=x;
unsigned t=-int(x>>31);
x+=x;
x^=t;
unsigned h=(x>>17);
h++;
h*=h;
h+=h;
x-=h;
x^=s;
return x;
}
int approximate_sin2(unsigned x)
{
unsigned s=-int(x>>31);
x+=x;
x^=s; //x=0..0xffffffff
x>>=16; //x=0..1
x*=0xffff^x; // x=x*(2-x)
x+=x;
return x^s;
}
The following C version executres in 32 cycles:
int approximate_sin3(unsigned x)
{
unsigned s=-int(x>>31);
x+=x;
x=x>>16;
x*=x^0xffff; // x=x*(2-x)
x+=x; // optional
return x^s;
}
The following i86 assembler version executes in 11 cycles:
add eax,eax // eax=phase sbb ebx,ebx mov ecx,eax xor eax,-1 // not eax mul ecx //add edx,edx // optional, use if you want output 32bit instead of 31 bit xor edx,ebx // edx=sin(phase)
Note that the assembley versions use the full 32 bits of input phase whereas the C versions only use 16 bits of input phase.
A 6th Order Piecewise Polynomial Approximation
Olli contributed the following 6th order approximation, which he measured as taking 16 clock cycles on Athlon 700MHz. His calculations indicate that the spectrum has a 3rd harmonic at -66db, and that the remaining harmonics are too low to be noticed.
lea EAX, [EBX*2+80000000h] //EAX = 1.31 : x = -1..1 sar EAX, 2 //EAX = 3.29 : x = -1..1 imul EAX //EDX = 6.26 : x^2 = 0..1 sar EBX, 31 //EBX = sign lea EAX, [EDX*2-14*8000000h] //EAX = 5.29 : x^2-14 = 0..1 lea ECX, [EDX*8+EDX-24000000h] //ECX = 3.29 : x^2-1 = -1..0 imul EDX //EDX = 11.21 : x^4-14x^2 xor ECX, EBX //ECX = 3.29 : sign*(x^2-1) = -1..1 lea EAX, [EDX*8+EDX+61*1200000h] //EAX = 8.24 : x^4-14x^2+61 imul ECX //EDX = 11.21 : (x^2-1)(x^4-14x^2+61)

Spectrum of Olli’s 6th Order Approximation
The following version takes 32-bit x and outputs float y. It is the same 6th-order approximation as above. The output range is -61..61, but can be normalized to -1..1 by uncommenting the three marked instructions. Olli measured the routine as taking around 13 clock cycles (without the normalization) on his Athlon.
By following the instructions in the comments this float->float approximation can be turned into int->float.
float x; // float input -pi..pi, UNCOMMENT IFF FLOAT INPUT! //int x; // 32-bit int input, UNCOMMENT IFF INT INPUT! float y; // float output const float c = 0.63661977236758134307553505349f; // UNCOMMENT IFF FLOAT INPUT //const float c = 1.0/0x40000000; // UNCOMMENT IFF INT INPUT const float c40 = 40; const float c6 = 6; const float c96 = 96; const float scale = 1.0f/61; fld x // UNCOMMENT IFF FLOAT INPUT //fild x // UNCOMMENT IFF INT INPUT fmul c // +-x fld st(0) // +-x, +-x fabs // x, +-x fld st(0) // x, x, +-x fmul st(0), st(0) // x^2, x, +-x fxch // x, x^2, +-x fsub c6 // x-6, x^2, +-x fmul st(0), st(1) // (x-6)*x^2, x^2, +-x fadd c40 // (x-6)*x^2+40, x^2, +-x fmulp st(1), st(0) // ((x-6)*x^2+40)*x^2, +-x fsub c96 // ((x-6)*x^2+40)*x^2-96, +-x //fxch // ************************ //fmul scale // *** Optional scaling *** //fxch // ************************ fmulp st(1), st(0) // +-(((x-6)*x^2+40)*x^2-96)*x fstp y
Iterative Methods
The Don Cross link in the resources section provides a good explanation of iterative techniques. Bram DeJong has suggested that I talk about stability issues, and methods for changing frequency on the fly – I’ll do this later, or someone else is welcome to.
Fun Stuff
Recursive FM
Patrice Tarrabia suggests the following two methods for generating non-bandlimited waveforms. He notes that the brightness parameter (k) needs to be carefully tuned. Using this technique it should be possible to build an oscillator which can morph between square and saw like waves.
y = sin( x + k*y ); //saw-like waveform, k controls brightness y = sin( x + k * y*y ); // square-like waveform
Other Stuff
Basile Graf sent in this Even Polynomial Sin Approximation C code with a maximal error of one LSB in 16bit audio.
Related Resources
- Olli Niemitalo’s Simultaneous Parabolic Approximation of Sin and Cos
- Olli Niemitalo’s Sine Wave Look-up Table Generation (using compressed deltas)
- Don Cross’ Optimising Trig Calculations
- Simple SSE and SSE2 (and now NEON) optimized sin, cos, log and exp
Acknowledgements
Thanks to René G. Ceballos from rgcAudio for doing all the hard work with the performance analysis, and making all the images and sounds so far.
